出于学习的需要,安装了 Debian etch,并升级到了 unstable,使用中遇到了几个小问题:
- /dev/rtc 有问题
# hwclock --utc --systohc
select() to /dev/rtc to wait for clock tick timed out
经 Google 发现是系统使用的 rtc.ko 内核模块的问题,使用 genrtc.ko 就没有问题,于是修改 /etc/modprobe.d/pnp-hotplug 中的 alias pnp:dPNP0b00 rtc 为 alias pnp:dPNP0b00 genrtc,解决问题。
- Gnome Terminal 的标题不能随着当前目录的路径动态变化了
经检查是 Debian 没有设置 PROMPT_COMMAND 这个环境变量造成的,在 /etc/profile 中设置即可
export PROMPT_COMMAND='echo -ne "\033]0;${USER}@${HOSTNAME%%.*}:${PWD/$HOME/~}\007"'
绩效评估,计算工作时间,顺便就拿 VIM 来说事吧,在 VIM 中变个小魔术,完成这个小任务;)
原始材料是这样的:
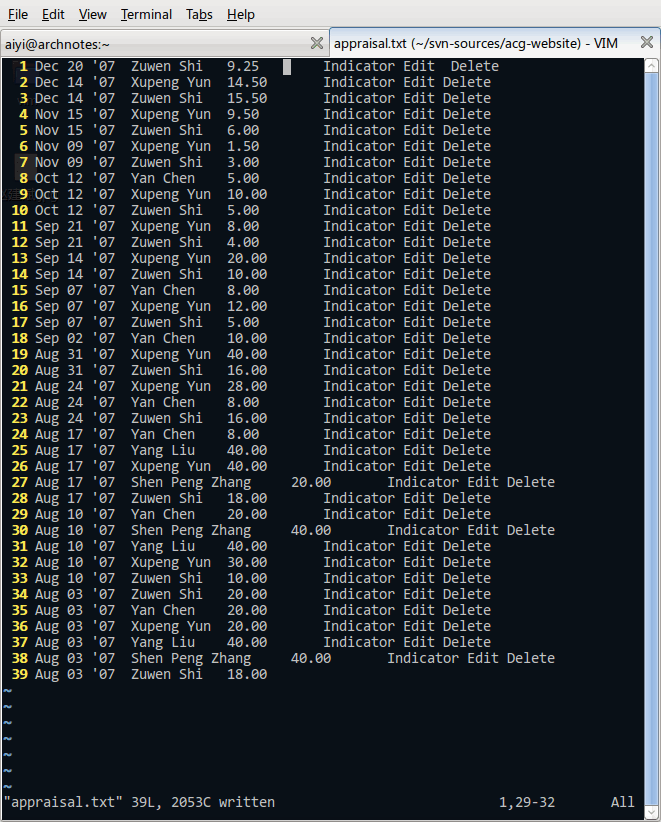
这是原始的按照时间顺序进行的统计。我想要的结果是,分别计算出每人的工作时间,那么第一步,去掉每行末尾的 “Indicator Edit Delete”。
首先录制一个宏,可以在命令模式下使用这样的按键序列:ggqd0fId$jq
把这串按键序列分开来开是这样的意思:
- gg: 回到文件的第一行
- q: 开始录制一个宏
- d: 定义了宏的名字是 d
- 0: 回到行首
- fI: 光标在行内移动到第一个 I 字符处
- d$: 删除从光标处到行尾的所有字符
- j: 移动到下一行
- q: 结束宏的录制
okay,宏录制完了,把它绑定到 F7 键上,这样子:
:map <F7> @d<Enter>
这是一个冒号命令,就是在命令模式下,依次输入上面的按键(<Enter>指代回车),好,现在可以一直按着 F7 键不动,很快文件就变成了下面的样子:
今天终于把本本的内存升级到了 4G,其实 2G 内存在日常工作和娱乐中已经足够使用了,甚至大部分时间都是用不完的,之所以要升级到 4G,是因为我需要跑一些虚拟机,用来做测试和学习,这样原本充足的内存就有点捉襟见肘了,还有另外一个原因是:现在内存挺便宜(285 一条 2G),哈哈
virt-manager是一个用来管理虚拟机的软件,现在可以支持xen、 qemu和kvm,使用它可以简化虚拟机的建立、监控和管理工作。
我想在archlinux下使用virt-manager,不过archlinux官方仓库里没有virt-manager的软件包,aur里目前也没有pkgbuild,没有办法,只能自己动手了,总共有四个相关的软件包:libvirt、 virtviewer、 virtinst和virt-manager,我现在已经把这个四个软件包的pkgbuild提交到了aur,在这里可以看到,也可以使用yaourt直接安装。
yaourt -S virt-manager
实际上,virtviewer这个软件原本的名字应该是virt-viewer,奇怪的是,在我向aur提交virt-viewer的pkgbuild时,总是告诉我不能覆盖virt-viewer这个包,但是事实上archlinux官方的软件仓库和aur里都没有叫这个名字的包,很无奈只有把它重命名为virtviewer提交了上去,至少现在可以用了;)
嗯,如果你也需要virt-manager,并且你也使用这些pkgbuild的话,别忘了给它们投一票,进了官方仓库就不用这么麻烦自己build啦。
问题:
我有这样的一个列表:
['a.b.c.d11u.e.f.g', 'e.f88.g', 'caa3.z.brr', 'z.48.ff.ee']
需要找节点最多的一个(节点间由.分割)
看似简单的工作,要用 Pythonic 的方法来做,还是要对 Python 的内置函数有一定程度的熟悉,比如这里可以用最熟悉不过的max,但是会用到它并不常用的可选参数:key
node_list = ['a.b.c.d11u.e.f.g', 'e.f88.g', 'caa3.z.brr', 'z.48.ff.ee']
max_node = max(node_list, key=lambda n: n.count('.'))
在这里,使用key参数改变了max比较列表元素的方法,达到了完成任务的目的。